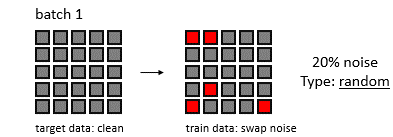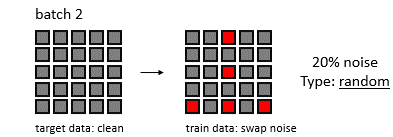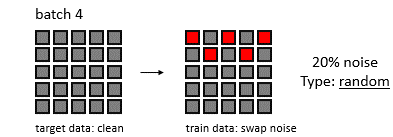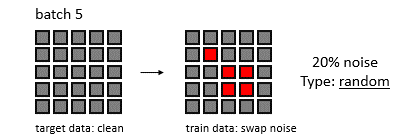
Machine learning is a rapidly evolving field with numerous algorithms designed to tackle various data science challenges. This article provides an overview of 101 machine learning algorithms, categorized by their primary functions.
Classification Algorithms
Classification algorithms predict outcome classes for given datasets. Here are some key examples:
- Logistic Regression: A statistical method for predicting binary outcomes.
- Naive Bayes: A probabilistic classifier based on Bayes’ theorem.
- Support Vector Machines (SVM): Algorithms that create a hyperplane to separate classes.
- K-Nearest Neighbors (KNN): Classifies based on the majority class of nearest neighbors.
- Decision Trees: Tree-like models of decisions and their possible consequences.
Regression Algorithms
Regression algorithms examine relationships between variables. Some popular regression algorithms include:
- Linear Regression: Models linear relationships between variables.
- Polynomial Regression: Fits a nonlinear relationship to data.
- Ridge Regression: Linear regression with L2 regularization.
- Lasso Regression: Linear regression with L1 regularization.
- Elastic Net: Combines L1 and L2 regularization.
Neural Networks
Neural networks are artificial models inspired by the human brain. Some common types include:
- Perceptron: The simplest form of neural network.
- Multilayer Perceptron (MLP): A feedforward network with multiple layers.
- Convolutional Neural Networks (CNN): Specialized for processing grid-like data.
- Recurrent Neural Networks (RNN): Process sequential data with loops.
- Long Short-Term Memory (LSTM): A type of RNN that can learn long-term dependencies.
Anomaly Detection
Anomaly detection algorithms find rare occurrences or suspicious events in data:
- Isolation Forest: Isolates anomalies in the feature space.
- One-Class SVM: Learns a decision boundary to classify new data as similar or different.
- Local Outlier Factor (LOF): Measures local deviation of density of a given sample.
Dimensionality Reduction
These algorithms reduce the number of random variables in a dataset:
- Principal Component Analysis (PCA): Reduces dimensions by finding orthogonal linear combinations.
- t-SNE: Visualizes high-dimensional data in 2D or 3D space.
- Linear Discriminant Analysis (LDA): Finds a linear combination of features to separate classes.
Ensemble Methods
Ensemble methods combine multiple algorithms to improve overall performance:
- Random Forest: Combines multiple decision trees.
- Gradient Boosting: Builds models sequentially to correct errors.
- AdaBoost: Adjusts weights of instances to focus on hard-to-classify examples.
Clustering Algorithms
Clustering assigns labels to unlabeled data based on patterns:
- K-Means: Partitions data into K clusters based on centroids.
- DBSCAN: Density-based clustering for discovering clusters of arbitrary shape.
- Hierarchical Clustering: Creates a tree of clusters.
Association Rule Learning
These algorithms uncover associations between items:
- Apriori Algorithm: Finds frequent itemsets in a database.
- FP-Growth Algorithm: An improved method for mining frequent patterns.
Regularization Techniques
Regularization prevents overfitting:
- L1 Regularization (Lasso): Adds absolute value of magnitude of coefficients as penalty term.
- L2 Regularization (Ridge): Adds squared magnitude of coefficients as penalty term.
- Elastic Net: Combines L1 and L2 regularization.
This comprehensive list of 101 machine learning algorithms covers a wide range of techniques used in data science. For more detailed information on each algorithm and when to use them, refer to the cheat sheets provided by Scikit-Learn.
Sources
101 Machine Learning Algorithms: A Comprehensive Guide