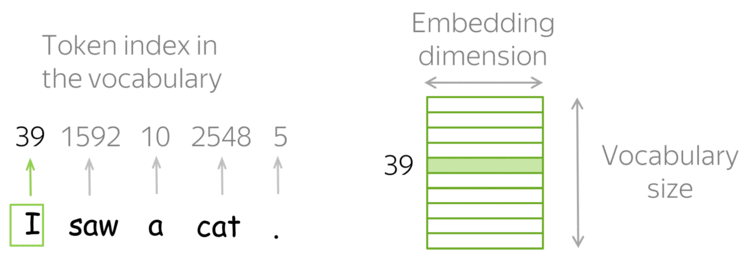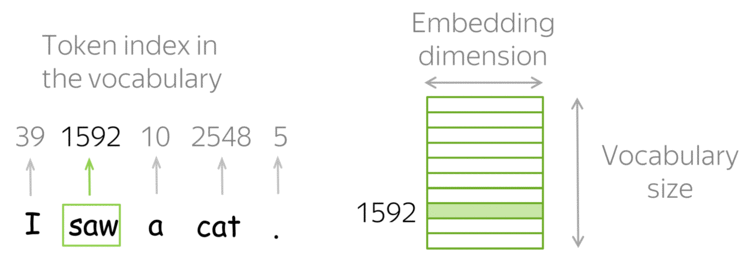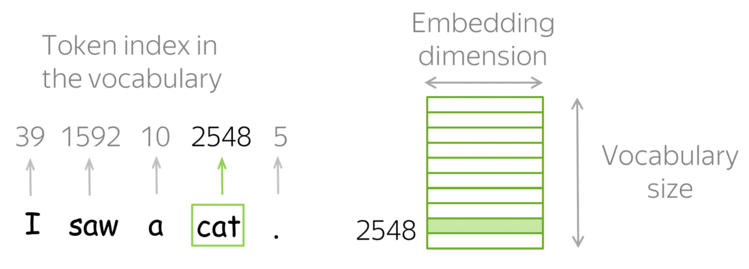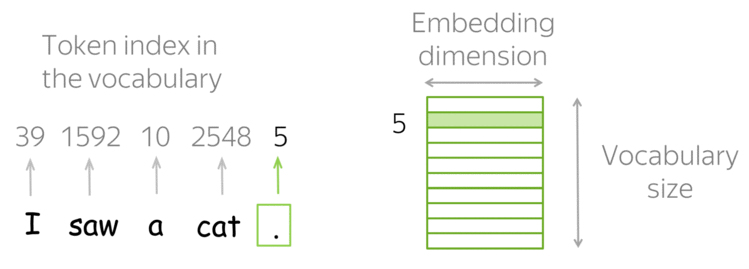
Data scientists and analysts often spend significant time cleaning and preparing data before analysis. The Skrub library emerges as a powerful solution for streamlining this process, offering efficient tools for data wrangling and preprocessing.
Key Features
Data Type Handling
The library excels at managing various data types, from categorical variables to numerical data, with built-in support for handling null values and unique value identification[1].
Automated Processing
Skrub’s standout feature is its ability to process complex datasets with minimal manual intervention. The library can handle diverse data structures, including employee records, departmental information, and temporal data[1].
Statistical Analysis
The library provides comprehensive statistical analysis capabilities, offering:
- Mean and standard deviation calculations
- Median and IQR measurements
- Range identification (minimum to maximum values)[1]
Real-World Application
To demonstrate Skrub’s capabilities, consider its handling of employee data:
- Processes multiple data types simultaneously
- Manages categorical data like department names and position titles
- Handles temporal data such as hire dates
- Provides detailed statistical summaries of numerical fields[1][2]
Performance Metrics
The library shows impressive efficiency in handling large datasets:
- Processes thousands of unique entries
- Maintains data integrity with zero null values in critical fields
- Handles datasets with hundreds of unique categories[1]
Integration and Usage
Skrub seamlessly integrates with existing data science workflows, focusing on reducing preprocessing time and enhancing machine learning pipeline efficiency. Its intuitive interface makes it accessible for both beginners and experienced data scientists[2].
This powerful library represents a significant step forward in data preprocessing, living up to its motto: « Less wrangling, more machine learning »[2].
Sources
[1] https://skrub-data.org/stable
[2] https://skrub-data.org/stable/auto_examples/00_getting_started.html