https://cameronrwolfe.substack.com/p/practical-prompt-engineering-part
- Prompt engineering: An empirical science focused on optimizing LLM (Large Language Model) performance through various prompting strategies.
- Aims to understand prompting mechanics and employs techniques to enhance LLM capabilities.
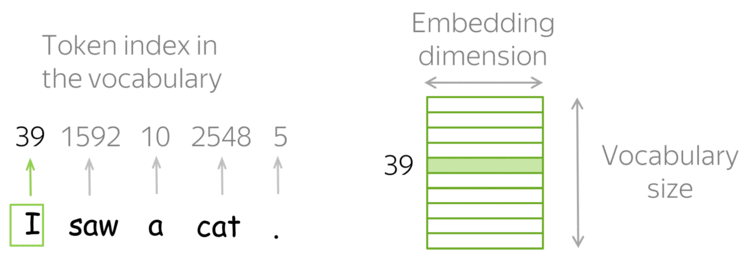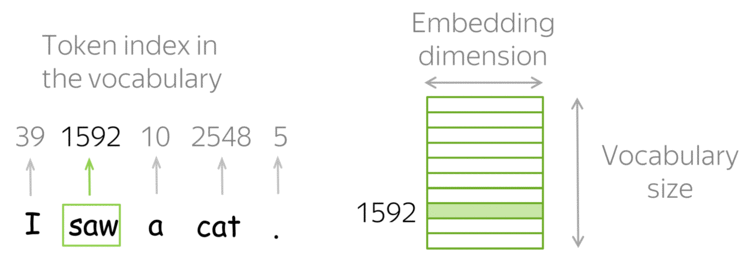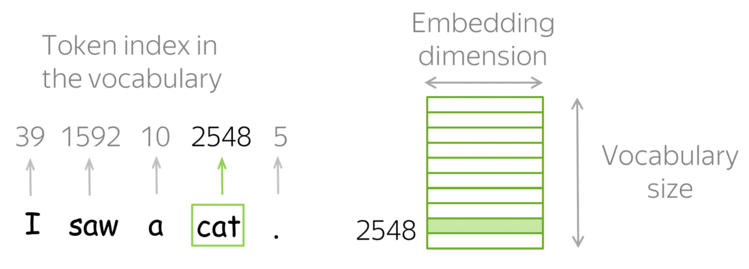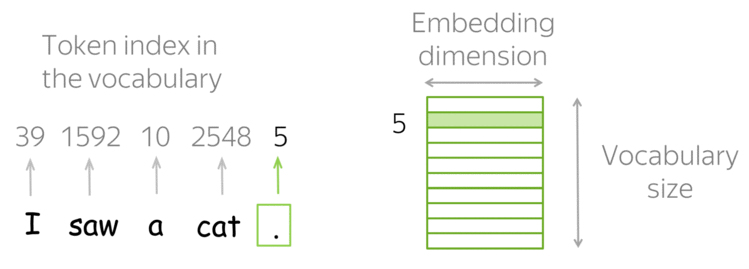
- Zero/few-shot learning: A fundamental technique where LLMs perform tasks with minimal or no training examples, showcasing their remarkable adaptability.
- Instruction prompting: Another vital technique involving explicit instructions in prompts to guide LLM behavior.
- Overview intends to impart practical insights and strategies for effective prompt engineering and LLM utilization.
- Provides actionable tricks and takeaways for prompt engineers and LLM practitioners to enhance their effectiveness.