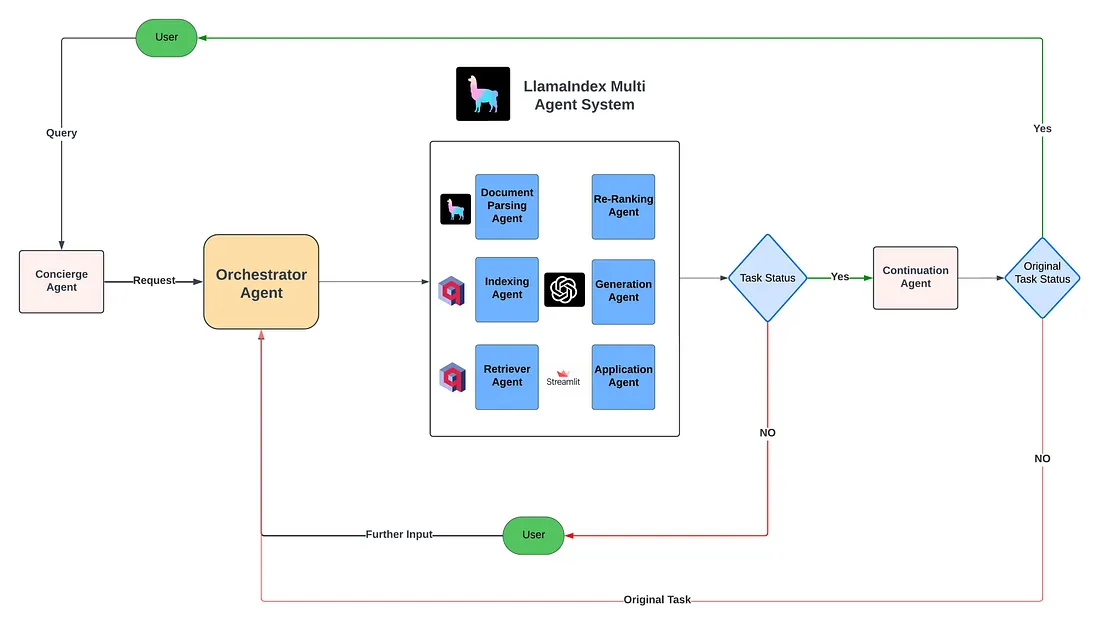
Transforming RAG with LlamaIndex Multi-Agent System and Qdrant
Retrieval-Augmented Generation (RAG) models have evolved significantly over time. Initially, traditional RAG systems faced numerous limitations. However, with advancements in the field, we have seen the emergence of more sophisticated RAG applications. Techniques such as Self-RAG, Hybrid Search RAG, experimenting with different prompting and chunking strategies, and the evolution of Agentic RAG have addressed many of the initial limitations.